搜索引擎排序算法改进基于页面分块
一、传统搜索引擎排序算法概述
1. 1 搜索引擎排序算法概述
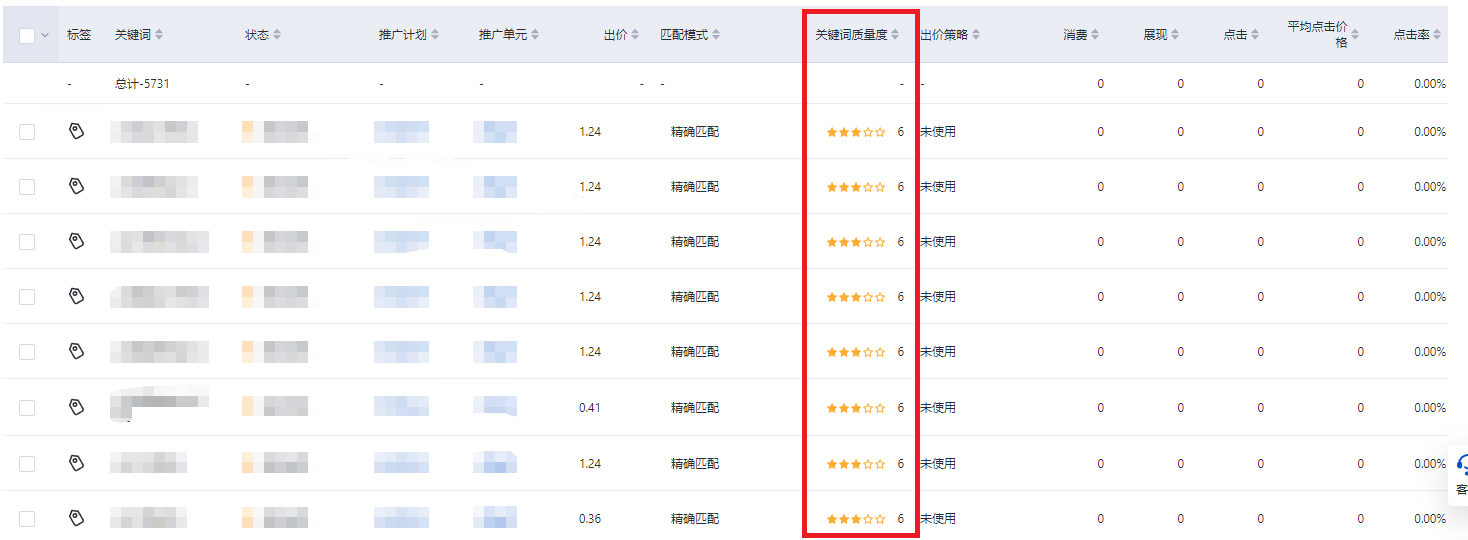
搜索引擎查询的结果是按照一定的规则排序供用户查看,这种规则就是搜索引擎排序算法。目前几种比较通用的搜索引擎排序算法有Direct Hit 排序算法、PageRank、排名竞价服务和词频位置加权排序算法.Direct Hit 排序算法是一种动态排序算法, 搜索引擎返回的排序结果根据用户的点击和网页被浏览的时间进行变化. PageRank 是著名搜索引擎Google 使用的排序算法,利用了网页的链接结构进行计算网页的PR 值进行排序。竞价排名服务是一些网站购买关键字排名, 搜索引擎按照点击( 也有按照时间段) 进行计费的一种服务。词频位置加权排序算法是一种从关键字出现次数和位置考虑进行排序的算法,文章主要讨论词频位置加权排序算法。

1. 2 词频位置加权排序算法
词频位置加权排序算法是网页排序中基础的算法, 著名的开源全文检索包Lucene 的基础排序算法思想就是词频位置加权排序, Lucene 在搜索引擎中得到了广泛的应用, 德国的网站检索系统Ifinder和开源搜索引擎Nutch 等大量搜索引擎基于Lucene 进行检索排序.词频位置加权排序算法以一个关键词与网页的相关度大小作为排序标准, 而关键词在网页中的相关度则由它在网页中出现的频数和位置两个方面加权计算得出. 该排序算法实现的基本步骤是: 采集网页、解析出网页的各个部分、过滤停用词、获得关键词、根据关键词的位置和频次加权得出查询词与网页的相关度、按照相关度排序展现给用户.可以看出, 该方法获取的是整张网页的关键词在广告和导航信息大量存在的现实中相关度的计算受到了极大影响. 如果能对网页进行分块并按一定的算法尽量的去除广告和导航等噪音信息, 将会有效提高相关度计算的准确度.
二、 网页分块算法介绍
目前对网页进行分块方法的研究已有很多,其中比较有效的是由微软亚洲研究院提出的VIPS( Vision based Page Segmentation ) , 笔者只讨论VIPS. VIPS 算法中Web 页面的结构定义如下:将网页看作一个三元组。
将网页看作一个三元组
其中表示给定页面上的所有的语义块的集合, 这些语义块之间没有重叠覆盖, 而每一个语义块又可以被定义为前面所描述的三元组
如此迭代循环.
表示当前页面上的所有的分隔条的集合. 事实上, 一旦确定了一个页面上的两个语义块, 那么这两个语义块之间的分隔条也就被确定了. 当然, VIPS 中的分隔条并不是真正存在的分隔条, 而是虚拟. 分隔条包括水平分隔条, 包括垂直分隔条. 每一个分隔条都具有一定的宽度和高度.
则描述了集合中两个语义块之间的关系, 这种关系可以描述为
其中每个δ都是一个形如( v i , v j ) 二元组, 其表示块vi 和v j 之间存在一个分割条.
VIPS 利用Web 页面的视觉提示如背景颜色、字体颜色和大小、边框、逻辑块和逻辑块之间的间距等, 并结合DOM 树进行页面分块. 它具有三个步骤: 页面块提取、分隔条提取以及语义块重构. 这三个步骤联合一起作为一次语义块检测的完整步骤.Web 页面首先被分割为几次比较大的语义块, 同时这几个语义块所组成的层次结构将被记录下来. 对于检测出来的每一个大的语义块分块过程又可以继续进行, 直到语义块的Doc( Deg ree of coherence) 值达到预先设定的Pdoc( Permit ted degr ee of coherence) 为止. VIPS 分割效果见图1.
三、搜索引擎排序算法改进
3. 1 网页净化规则
网页分出块以后, 如何判别语义块中的广告、导航条等噪声网页块是净化网页从而提高搜索引擎排序准确度的关键问题. 通过大量的统计和分析, 利用网页块的文字和链接数量、网页块的空相对间位置和网页块内容属性, 笔者总结出三条规则识别噪声语义块.首先定义网页窗口原点坐标为网页的左上顶角, 网页块中心横坐标X 为该块中心点在窗口中的横坐标, 还有网页块中心纵坐标Y, 网页宽度M, 网页高度N . 通过网页块的相对空间位置来定义网页空间位置, 其定义为
( 1) 网页分块在网页的上、下、左和右位置, 文字数量与链接数量的比小于F1 , 则该块为噪音分块.
( 2) 网页块在中间位置, 文字数量与链接数量的比小于F2 , 则该块为噪音分块.
( 3) 如果网页块整块内容为Flash 文件, 判断该块为噪音块.
( 4) 网页中含有行数超过3 的T ex t 控件, 判断该块为噪音块.
3. 2 改进的排序算法描述
本算法采用VIPS 对网页进行分块, 并利用制定的规则净化网页, 从而达到优化排序算法的目的.具体算法如下:
输入: 网页库P 和查询Q, 阈值F1 , F2 , R1 , R 2 ,R3 , R4 .
输出: 排好序的页面集合Sp .
( 1) 统一化网页, 规整网页中不规则的标签.
( 2) 对网页P i 利用VIPS 进行分块.
(3) 利用规则判断和去除网页中的噪音, 达到净化网页的目的.
( 4) 过滤停用词.
( 5) 获取关键词.
( 6) 利用关键词的位置和频次加权计算出查询词Q 与网页P i 的相关度.
( 7) Return Sp .
从算法中可以看出, 所有文档都是经过净化再去参加相关度的计算, 而且是在用户进行检索时实时计算出来的. 式( 1) 为词频位置加权算法的典型公式, 用于计算某文档对应于用户查询关键字的得分。
式中: sj 为文档j 对应于用户查询词的得分; cj 为文档j 中包含的所有可供查询的词条数量; tij 为查询词i 在文档j 中出现的频率; f i 为查询词i 在文档中出现的倒排词频; b 为在索引过程中设置的字段参数, 通常为1. 0. 其中和文档无关, 不会影响文档的排名. 式( 2) 中l j 为文档j 的长度, 可以看出经过网页分块并净化网页后, 对r 的影响比较大, 而r 为式( 1) 中影响排序得分的重要因素. 假设有两篇文本内容如下:
a. tx t: I am a student . Her e is an advert isement.
b. txt : I am a student.
根据式(2) , 可算得r 分别为0. 312 5 和0. 5.b. txt 为a. txt 去除了广告主题后的内容, 可以看出b. txt 中内容的r 得到了提高, 从而整个的排序得分提高. 经过网页分块、净化后, 改进算法用净化后的网页代替整张网页参与检索, 提高排序的正确性。
 上一篇
上一篇